Training Claude on the Job
Feb 2026
← NotesHow I built a system that carries what Claude learns about me from one session to the next.
The Problem
Claude Code has built-in memory now. It writes notes to itself as you work and loads them back at the start of each session. That covers the basics. But it decides what to save without asking you, it doesn't sync across machines, and there's no version history. For casual use that's fine. For someone using it daily as a core part of how they work, the gaps add up.
How I Think About It
The mental model that helped me most: think of Claude as a new employee you're training on the job. They're capable. They pick things up fast. But they need context about how you operate, what your standards are, what you've already decided. Without that, they default to their own judgment, which is often good but not calibrated to you.
The difference is that with an actual employee, that training happens passively over months. With Claude, I can make it deliberate and structured.
How It Works
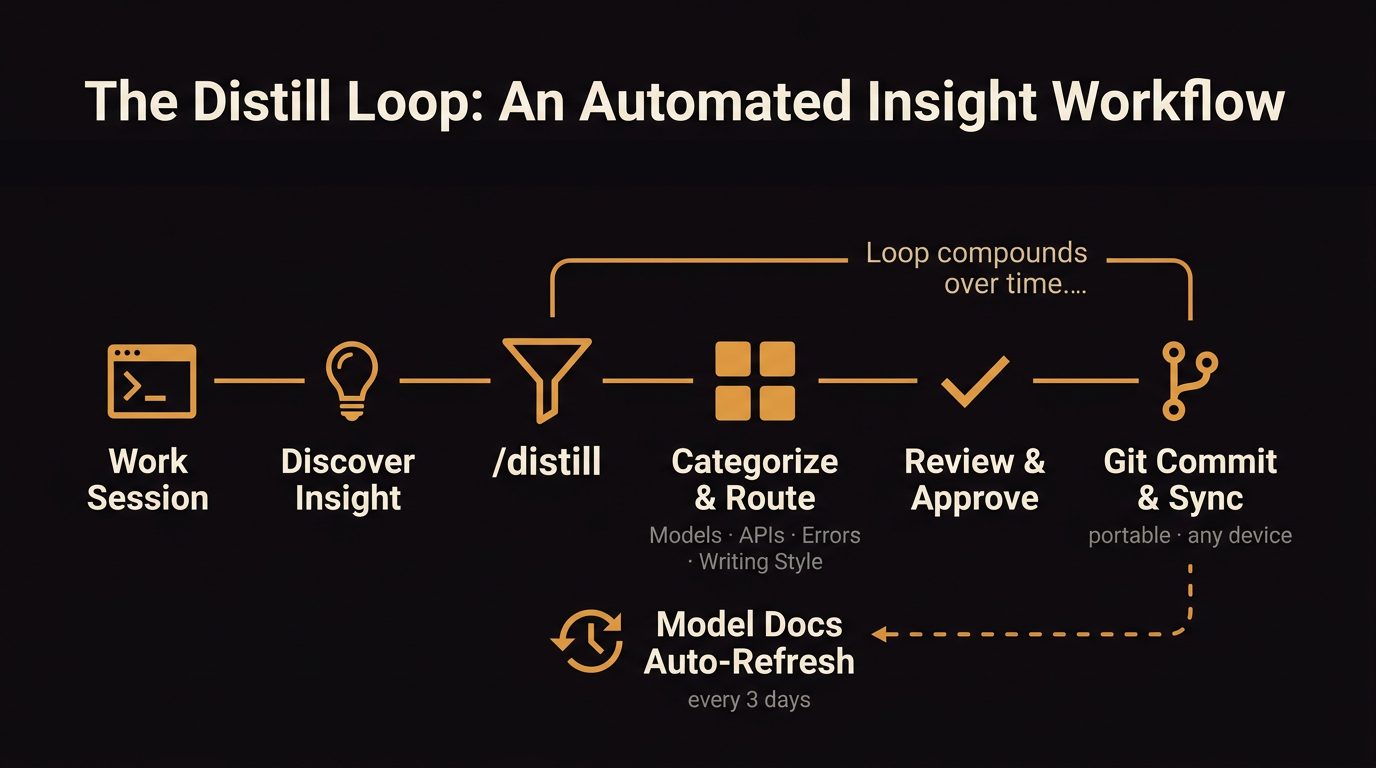
At the end of a session, I run a command:
It reviews what happened in the conversation and surfaces anything worth keeping — a preference I stated, a pattern I corrected, a tool behavior I confirmed. It proposes each one individually as a change before writing anything. I approve or reject. Nothing gets saved without my sign-off.
Approved learnings get committed to a git repo. A setup script handles cloning the repo and copying everything into the local files Claude Code reads from: CLAUDE.md, skills, writing style rules. On a new machine, I run the script and Claude arrives with the same calibration. Over time, it accumulates: which LinkedIn structures I've passed on, which chart library I've standardized on, how to route to Gemini instead of Claude to save cost.
What Gets Captured
- —Writing patterns I've corrected — for example, I flagged that curiosity-gap hooks on LinkedIn posts feel manufactured regardless of how they're phrased, with the specific constructions noted and why each one was rejected
- —Model and tool preferences — which model for which task, when to route to Gemini instead of Claude to save cost
- —Workflow decisions — how I like to structure certain tasks, what order I want things done in
- —Error patterns — things that have gone wrong before and how I resolved them
Here's what that looks like in practice. After a session refining outreach emails, the distill command surfaced seven learnings and asked me to approve or reject each one:
Each card shows what was learned, where it would be saved, and how broadly it applies. I approve the ones worth keeping and reject the rest. Nothing writes without my sign-off.
None of it is permanent. If something turns out to be wrong or outdated, I update or remove it the same way it was added.
Why Not Just Use the Built-In Memory?
Auto memory works by having Claude decide what's worth saving as you work. It writes notes to itself about patterns it notices, commands you use, preferences you express. The problem is the lack of a filter. Claude is making judgment calls about what matters without you reviewing them. Over time the memory fills with things that were relevant once, half-formed observations, and context that no longer applies.
It's also machine-local. There's no version history, no way to sync it across devices, and no way to selectively share parts of it. If something gets saved wrong, you'd have to notice and manually edit the file.
Distillation sits on top of that gap. Nothing gets written without me approving it. The learnings are categorized by type, versioned in git, and available wherever I clone the repo. I can share just my writing style rules with a collaborator without including API keys or personal config.
Where Distillation Fits
Claude Code has a built-in context system. Your CLAUDE.md file loads every session. It's where you write instructions: coding standards, preferences, how you want things done. Auto-memory also loads every session. That's where Claude writes notes to itself about your project, up to 200 lines, without asking you. Then there are skills, which are reusable instructions that only load when invoked or when Claude decides they're relevant to what you're working on.
What I built sits on top of that. Distilled learnings get written into my CLAUDE.md itself, which means they load every single session, unconditionally. The /distill command is a skill (it loads on demand when I invoke it), but the learnings it produces go into CLAUDE.md (always loaded). That's the architectural difference. A skill teaches Claude how to commit code. A distilled learning tells Claude I never want em dashes in my writing. One loads sometimes. The other loads always.
The whole system lives in a git repo. On a new machine, I run the setup script. It clones the repo and installs everything to where Claude Code reads from. Claude arrives calibrated.
The Review Gate
The other difference is who decides what gets saved. Auto-memory is passive. Claude writes notes to itself during your session. You can read and edit them after the fact, but there's no approval step before they're written.
Distillation inverts that. At the end of a session, the command surfaces what it thinks is worth keeping. Each learning gets categorized, assigned a destination file, and shown to me individually. I approve or reject. Only approved entries get committed.
This Isn't a New Idea
Other people have built versions of this. Anthropic staff use a diary and reflection system to auto-update their context files. There are open-source plugins that capture session context, compress it, and inject it back automatically.
Most of those systems are fully automated. The thing I value in my version is that nothing saves without my approval. Automated memory accumulates wrong things confidently. The approval gate is the point.
The Bigger Principle
The goal was never to make Claude smarter. It was to stop wasting time re-establishing context that already existed — and to own that context outright rather than depending on a platform to maintain it for me.